Accelerating NLP Model Inferencing with DistillBERT & ONNX
Balancing speed and accuracyExpedia Group™️ acts as a booking agent for all sorts of travel. An issue we’ve wrestled with is when a hotel (or vacation rental, activity, etc.) shares public contact information through our platform that allows for direct booking. This act violates our service agreements and we must detect if it happens. Furthermore, this mechanism needs to scale to review an ongoing stream of data generated by bookings, website updates, client updates, etc.
This is not a unique problem in the travel industry. It can be generalized to verify a whole class of financial and legal agreements on an ongoing basis. Speed is of the essence; quickly detecting violations protects the platform’s viability and stops possible fraud.
We require real-time decisions from unstructured data but would a large language model be up to the task? We started with BERT [1], the open-source transformer-based machine learning model for Natural Language Processing(NLP). After running sample data, we discovered it could give us inferences reliably — but was too slow.
In fact, there was no way to get results within the constraints of our service-level agreement (SLA). Simulating each call with listing descriptions of 500 words or more, the model took up to 2 seconds. The speed was too slow for upstream services and didn’t meet the 250 milliseconds SLA we promised.
This was when we embarked on a journey to improve speed while maintaining inference reliability. We went straight to standard model compression techniques which are readily available and with which we were already familiar:
- Knowledge Distillation (KD) Teacher-to-student transfer reduces model size.
- Graph compression using Open Neural Network Exchange(ONNX) allows for data transfer to many different environments. It also has training capabilities.
- Using specialized hardware like GPU/Xeon processors through AWS exchange
We used these techniques to improve speed without significantly impacting the model’s accuracy.
A Bit About Knowledge Distillation (KD)
In machine learning, Knowledge Distillation refers to transferring knowledge from a large model to a smaller one. The end goal is to develop accurate models that are more computationally efficient.
In a nutshell, we want to transfer knowledge from larger models (e.g., deep neural networks) to smaller models (e.g., shallow neural networks).
One solution is to use a technique called Knowledge Distillation. This involves “distilling” the knowledge from your large model into a new one that’s smaller, more manageable, and easier to work with.
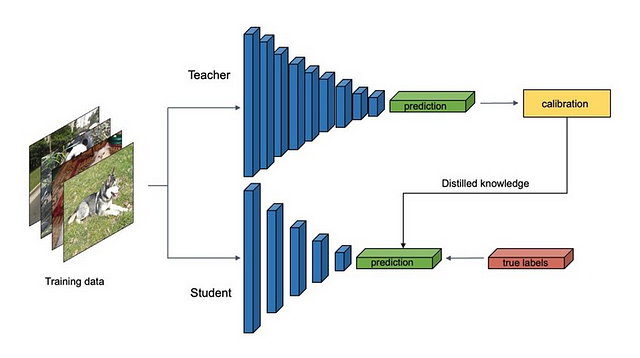
The general idea of performing KD is
- Use a pre-trained teacher model
- Take some training data on which you want to train the Student model
- Pass data through the Teacher model to generate soft labels (actual labels are “hard” labels)
- Train Student model on data + soft labels
There are several ways to distill the knowledge of the Teacher model into a simpler Student model. The main techniques are Multi-teacher, Offline, and Online.
Multi-teacher approaches benefit from more diverse data sources and, in some cases, less biased data. For offline KD, the Teacher is trained, and then the model is transferred directly to the Student. Conversely, online KD uses the ensemble result from multiple soft target Student models to generate a Student model.
Technique #1: Use DistilBERT instead of BERT
- DistilBERT [2] has the same general architecture as BERT, but only half the layers of BERT.
- DistilBERT was trained on eight 16GB V100 GPUs for around 90 hours.
- KD is done during the pre-training phase, reducing the size of BERT by 40% while retaining 97% accuracy and becoming 60% faster.
Technique #2: Convert the model to ONNX
- Convert the DistilBERT model to ONNX format.
- It is effectively a serialized format to represent the model and additionally functions as a model compression technique [3]
Technique #3: use a suitable AWS instance type
- Use inf1.6xlarge instance type to bring down latency further (published improvement of 2.3 X)
- 24 vCPU, 48 GiB memory
- 4 AWS Inferentia chips — dedicated to inference with a large on-board memory cache and speeds of 128 TOPS
- Much better than g4dn.2xlarge(GPU) & c5–9xlarge(compute intensive) instance types
Our request/response
Request
{
"transactionContext": {
"transactionId": "123456"
},
"attributes": {
"listingDescription": "Near Xel Casino and the Cosmo Casino, the Tenebian Resort Las Vegas provides a casino, a nightclub, and a grocery/convenience store. For those looking to try their luck, this resort boasts a sportsbook, 137 casino gaming tables, and 7 casino VIP rooms. Indulge in a hot stone massage, a manicure/pedicure, and hydrotherapy at City Ranch Spa + Fitness, the onsite spa. Be sure to enjoy a meal at any of the 21 onsite restaurants, which feature Asian cuisine and happy hour. Yoga classes and aerobics classes are offered at the gym."
}
}
Response
{
"modelCode": "DistilBertNLPSupplyListingDescHA",
"modelVersion": "1.0",
"refreshVersion": "v20211220",
"probabilityScore": "1.02e-10",
"modelSegment": "SUPPLY",
"topContributor": "listingDescription",
"scoreDetails": {
"label": "NonFraud"
}
}
Notes:
- Averaged over 12 different runs using Apache Jmeter, free Java open-source software for load testing
- Predictor service running on AWS ECS with 1 Fargate instance
More numbers
- Instance type used: inf1.6xlarge
- Each input request: 512 tokens
The bottom line was that our work was successful. We met both our accuracy and our latency goals. We were able to improve latency by 95%(2 sec to 110 milliseconds) and reduce the model size by 27% while impacting accuracy by only 1%.
Following this general procedure should work for a lot of common NLP challenges. As for us, we plan to use the three-step technique outlined above for various use-cases we have today. Then it’s off to the next challenge.