PySpark and Scala Spark
Apache Spark is written in Scala, and using PySpark, you can write Spark applications in Python.
Have you ever wondered how PySpark works even though the underlying framework i.e. Apache Spark is written in Scala?
The answer is that PySpark uses a library called Py4J. Py4J enables Python programs to access Java objects. So, PySpark offloads all the Big Data processing work to the Scala Spark framework. That means that PySpark is just an interface to use Apache Spark in Python.
Let’s ask a more deep and basic question: how does Python work? We keep hearing that Java programs run within a Java Virtual Machine(JVM), but what about Python?
The simple answer is that Python programs run in their virtual machine(implemented in C; hence Python is called CPython).
Back to how PySpark uses Scala Spark: Py4J provides a GatewayServer instance that allows Python programs to communicate with JVM through a local network socket.
We need to start the gateway so it can accept incoming Python requests:
GatewayServer gs = new GatewayServer(new StackEntryPoint());
gs.start();
Now, we can call Java methods from python code as if they were python methods:
from py4j.java_gateway import JavaGateway
gw = JavaGateway() # connect to the JVM
java_object = gw.jvm.mypackage.MyJavaClass() # invoke constructor
other_object = java_object.doThat()
gateway.jvm.java.lang.System.out.println('Hello World!')
One part of Py4J runs in the Python VM, so it is always “up to date” with the latest version of Python. The other part runs in the JVM we want to call.
P4J uses its protocol to communicate via sockets instead of JNI to optimize certain cases, manage memory, etc:
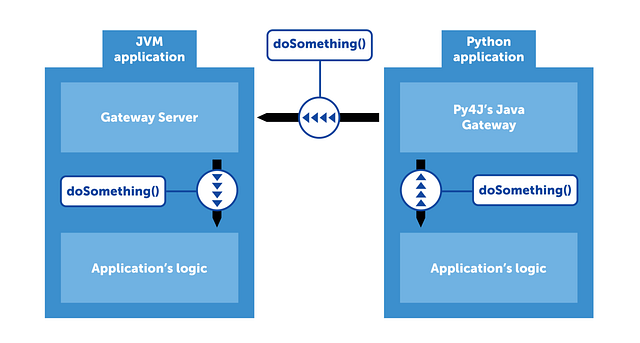
Exploring these enhanced my understanding of how things work under the hood. I hope this is helpful to you as well.
References